Машинная обработка естественных языков: Apache UIMA
Первоначально разработанная спецами из IBM, Архитектура управления неструктурированной информацией (UIMA) сейчас обитается в инкубаторе от Apache, являет собой образец открытого ПО и распространяется по апачевой лицензии.
Что это?
Это — программная инфраструктура, цель которой — анализ больших массивов информации и извлечение из этой информации знаний. Тут мы осторожно остановимся, заглянем в пропасть семантического веба, на дне которой лежит искусственный интеллект, и сделаем осторожный шаг назад.
Apache UIMA хороша тем, что не таит в себе никакой мистики. Всё можно пощупать, поковырять, подпилить.
Аннотаторы
Пример работы
В качестве примера возьмём разбор предложения из статьи «Automate Metadata Extraction for Corporate Search and Mashups» (автор Dan McCreary). Начнём с того, что научим программу понимать, что Sue и Susan – семантически близкие понятия. Рассмотрим два предложения:
Our client is going to sue your company.
This proposal was written by Sue Smith for the Johnson Corporation.
В первую очередь, проводим POS-анализ (part-of-speach, разбор по частям речи). Вот список идентификаторов, обозначающих части речи для английского языка.
На выходе pos-аннотатора получаем:
Разбираемся со вторым предложением. Воспользовавшись неким словарём (а использование словарей терминов и онтологий − неотъемлемый атрибут семантического поиска), узнаём, что Sue — это сокращённое имя Susan, а два идущих подряд существительных «Sue Smith» − возможно, сотрудник компании за номером 1234747 Susan Smith. Точно так же можем определить, что Johnson Corporation — это организация с идентификатором 347474. Фиксируем полученные знания:
for
the
Johnson
Corporation
.
Таким образом, в несколько итераций, мы обогащаем текстовую информацию, чем поднимаем поиск на новый уровень.
Никакой магии.
Аннотирование текста для машинного обучения

Что такое аннотирование текста?
Аннотирование текста — это процесс разметки текстового документа или различных элементов его содержимого. Какими бы умными ни были машины, человеческий язык иногда бывает сложно расшифровать даже самим людям. При аннотировании текста составляющие предложений или структуры выделяются по определённым критериям для подготовки наборов данных к обучению модели, которая сможет эффективно распознавать человеческий язык, коннотацию или эмоции, стоящие за словами.
Почему это важно?
Зачем мы вообще аннотируем текст? Последние прорывы в сфере NLP выявили нарастающую потребность в текстовых данных для таких областей, как страхование, здравоохранение, банковское дело, телекоммуникации и так далее. Аннотирование текстов необходимо, поскольку оно гарантирует, что целевая считывающая система, в данном случае — модель машинного обучения (ML), сможет воспринимать предоставленную информацию и делать выводы на её основе. Ниже мы подробнее рассмотрим конкретные способы использования, а пока вам следует помнить то, что текстовые данные всё равно остаются данными, почти как изображения или видео, и они так же используются для обучения и тестирования.
Как аннотируется текст: аннотирование текстов для NLP
Список задач, которые учатся выполнять компьютеры, стабильно растёт, однако некоторые области остаются нетронутыми: NLP не является в этом исключением. Без аннотаторов-людей модели не поймут глубины, естественности и сленга, при помощи которых люди управляют и манипулируют языком. Поэтому компании постоянно пользуются помощью живых аннотаторов для обеспечения достаточного качества данных для обучения. К современным ИИ-решениям на основе NLP относятся голосовые помощники, машинные переводчики, умные чат-боты, альтернативные поисковых движки, и список систем продолжает расширяться параллельно с повышением гибкости, обеспечиваемой типами аннотирования текста.
Аннотирование текста для распознавания текста
Визуальное распознавание текста (optical character recognition, OCR) — это извлечение текстовых данных из отсканированных документов или изображений (PDF, TIFF, JPG) в понимаемые моделью данные. Системы OCR предназначены для упрощения доступности информации пользователям. Они помогают в ведении бизнеса и в рабочих процессах, экономят время и ресурсы, которые были бы необходимы для управления данными. После преобразования обработанная OCR текстовая информация может более удобно и просто использоваться компаниями. Достоинствами распознавания текста являются отсутствие необходимости ручного ввода данных, снижение ошибок, повышение продуктивности и т.д.
Подробнее об OCR и областях его применения мы поговорим в отдельной статье. А пока главный вывод будет таким: OCR вместе с NLP — две основные области, сильно зависящие от аннотирования текста.
Типы аннотирования текста
Наборы данных аннотирования текста обычно представлены в виде выделенного или подчёркнутого текста, по краям которого оставлены заметки. В этом посте мы рассмотрим следующие основные типы аннотирования текста:
Аннотирование сущностей
Аннотирование сущностей служит для разметки неструктурированных предложений важной информацией; часто оно применяется в наборах данных для обучения чат-ботов. Этот тип аннотирования можно описать как нахождение, извлечение и разметка сущностей в тексте одним из следующих способов:
Распознавание именованных сущностей (named entity recognition, NER): NER лучше всего подходит для разметки в тексте ключевой информации, будь то люди, географические точки, часто встречающиеся объекты или персонажи. NER является фундаментальной основой NLP. Google Translate, Siri и Grammarly — прекрасные примеры NLP, использующего NER для понимания текстовых данных.
Разметка частей речи: как понятно из названия, разметка частей речи помогает парсить предложения и распознавать грамматические единицы (существительные, глаголы, прилагательные, местоимения, наречия, предлоги, союзы и т.п.).
Разметка ключевых фраз: этот способ можно описать как поиск и разметку ключевых слов или фраз в текстовых данных.
Хотя аннотирование сущностей является сочетанием распознавания сущностей, частей речи и ключевых фраз, оно часто идёт рука об руку с сопоставлением сущностей, что помогает моделям в более глубокой контекстуализации сущностей.
Сопоставление сущностей
Если аннотирование сущностей помогает находить и извлекать сущности из текста, то сопоставление сущностей, часто называемое сопоставлением именованных сущностей (named entity linking, NEL) — это процесс соединения этих именованных сущностей с более крупными наборами данных. Возьмём для примера предложение «Summer loves ice cream». Задача заключается в том, чтобы определить, что Summer — это имя девушки, а не время года или любая другая сущность, которую потенциально можно назвать Summer. Сопоставление сущностей отличается от NER тем, что NER находит именованную сущность в тексте, но не указывает, что это за сущность.
Классификация текста
Задача аннотирования сущностей заключается в аннотировании конкретных слов или фраз, а задача классификации текста — в аннотировании фрагмента текста или строк одной меткой. Примерами и специализированными типами классификации текста являются классификация документов, разбиение продуктов на категории, аннотирование эмоционального настроя текста и так далее.
Классификация документов: присвоение документу одной метки может быть полезным для интуитивной сортировки больших объёмов текстового содержимого.
Разбиение продуктов на категории: процесс сортировки продуктов или сервисов на классы и категории может улучшить поисковые результаты для электронной коммерции, например, оптимизировать SEO и повысить видимость продукта на странице ранжирования.
Аннотирование эмоционального настроя
Как понятно из названия, аннотирование эмоционального настроя заключается в определении эмоций или мнений, лежащих в основе текстового блока. Даже нам, людям, иногда сложно определить значение полученного сообщения, если тексту свойственен сарказм или другие виды языковых манипуляций. Представьте, что определять его приходится машине! За кулисами этого явления находится аннотатор, внимательно анализирующий текст, выбирающий метку, лучше всего описывающую эмоцию, настрой или мнение. Затем компьютеры могут основывать свои выводы на схожих данных, чтобы различать положительные, нейтральные или отрицательные отзывы, а также другие виды текстовой информации. В свете своей применимости анализ эмоционального настроя помогает компаниям разрабатывать стратегии позиционирования своего продукта или услуги и их дальнейшего отслеживания.
Способы применения аннотирования текста
Способы применения аннотирования текста почти столь же повсеместны, как и способы применения аннотирования изображений и видео. Почти каждая область, содержащая текстовые данные, может быть аннотирована и использована для обучения модели:
Здравоохранение
Аннотирование текста меняет правила игры в здравоохранении, где оно заменяет кропотливые ручные процессы высокопроизводительными моделями. В частности, оно влияет на следующие операции:
Страхование
Как и в здравоохранении, в области страхования аннотирование текста обеспечивает множество преимуществ.
Банковское дело
Повышение персонализации, улучшение автоматизации, снижение ошибок и адекватное использование ресурсов — всё это становится возможным благодаря модели, способной выполнять следующие задачи:
Телекоммуникации
Аннотированный текст автоматизирует человеческий труд в следующих областях:
Лучшие платформы аннотирования изображений для компьютерного зрения на 2019 год
Мы постоянно находимся в поиске лучших платформ аннотирования, обеспечивающих широкую функциональность, имеющих инструменты управления проектами и оптимизацию процесса аннотирования (когда нужно аннотировать 50 тысяч изображений, важна экономия даже одной секунды на каждом).
На основании своего опыта работы с каждой из платформ мы делимся своими честными обзорами, надеясь, что они будут полезны дата-саентистам, которым необходимо вручную размечать свои данные.
Мы используем следующие критерии:
1. LabelIMG
LabelImg — это инструмент для разметки изображений с открытым исходным кодом, имеющий готовые собранные файлы для Windows, благодаря чему его установка выполняется чрезвычайно быстро.
2. VGG Image Annotator
VGG — это инструмент в open-source, который подобно LabelImg способен потрясающе справляться с простыми задачами, не требующими управления проектами. У него есть онлайн-интерфейс, а также его можно использовать офлайн как HTML-файл. В самой последней версии есть широкий выбор инструментов для разметки видео.
3. Supervise.ly
Supervisely — это потрясающая веб-платформа, предоставляющая расширенный интерфейс аннотирования, а также обеспечивающая весь процесс обучения компьютерного зрения, в том числе и библиотеку моделей глубокого обучения, которые можно непосредственно обучать, тестировать и совершенствовать внутри платформы.
4. Labelbox
Labelbox — ещё одна отличная веб-платформа, запущенная в начале 2018 года и с тех пор постоянно обновляющая и улучшающая свои функции. Она также предлагает возможность интеграции живого оператора при помощи импорта прогнозов модели и наблюдения за консенсусом между разметчиками и моделью.
Как размечать данные для машинного обучения
Искусственный интеллект (ИИ, AI) двигает человечество в будущее, и чтобы иметь конкурентное преимущество, вам нужно быть к нему готовым.
Машинное обучение (МЛ, ML) — подмножество ИИ, позволяющее программным приложениям распознавать паттерны и делать точные прогнозы. Благодаря ML у нас есть беспилотные автомобили, фильтрация спама в электронной почте, распознавание дорожного движения и многое другое.
Для обучения высококачественных моделей ML необходимо предоставить их алгоритму точно размеченные данные.
В этом посте мы расскажем всё, что вам нужно знать о разметке данных, чтобы принимать осознанные решения для своего бизнеса. Пост отвечает на следующие вопросы:
Что такое разметка данных?
Разметка данных — процесс выявления объектов в сырых данных, например, в видео или на изображениях, и добавление к ним меток — помогает модели машинного обучения делать точные прогнозы и оценки. Например, аннотирование данных может помочь беспилотному транспорту останавливаться на пешеходных переходах, цифровым помощникам — распознавать голоса, а камерам безопасности — обнаруживать подозрительное поведение.
Как работает разметка данных?
Сбор данных
Всё начинается со сбора значительного объёма данных: изображений, видео, аудиофайлов, текстов и т.д. Большой и разнообразный объём данных гарантирует более точные результаты по сравнению с малым объёмом данных.
Разметка данных
Разметка данных — процесс выявления живыми людьми в неразмеченных данных элементов при помощи платформы разметки данных. Работникам можно дать задание определять, есть ли на изображении люди, или отмечать движение мяча в видео.
Контроль качества
Для создания качественных высокопроизводительных моделей ML размеченные данные должны быть информативными и точными. Для обеспечения качества размеченных данных необходимо организовать процесс проверки качества (QA), в противном случае модель ML не сможет успешно работать.
Обучение модели
Для обучения модели ML алгоритму ML передаются размеченные данные, содержащие правильный ответ. Благодаря только что обученной модели вы сможете делать точные прогнозы на новом наборе данных.
Какие оптимальные практики разметки данных существуют?
Используйте эти проверенные и протестированные практики разметки данных для выполнения успешного проекта.
Соберите разнообразные данные
Для минимизации перекоса данные должны быть как можно более разнообразными. Допустим, вам нужно обучить модель для беспилотного автомобиля. Если вы решите использовать для обучения модели данные, собранные в городе, то машина с трудом сможет перемещаться в горах. По той же причине снимайте изображения и видео под различными углами и с разными условиями освещения.
Собирайте конкретные данные
Чтобы не сбивать модель с толку, ваши данные должны быть конкретными. Кажется, что это противоречит предыдущему пункту, но на самом деле важно передавать модели ту информацию, которая ей необходима для успешной работы. Поэтому если вы обучаете модель робота-официанта, то используйте данные, собранные в ресторанах. Передача модели данных, собранных в торговом центре, аэропорту или больнице приведут к ненужному запутыванию.
Подготовьте процесс QA
Интегрируйте методики QA в свой конвейер проекта, чтобы оценивать качество разметки и гарантировать успешные результаты проекта. Это можно сделать несколькими способами:
Подготовьте инструкции по аннотированию
Напишите информативную, чёткую и краткую инструкцию по аннотированию, рассказывающую об инструментах и аннотировании, чтобы с самого начала работы избегать возможных ошибок. Иллюстрируйте разметку примерами: изображения помогают аннотаторам и QA понимать требования к разметке лучше, чем письменные объяснения. Также инструкция должна содержать конечную цель работы, чтобы показать сотрудникам картину в целом и мотивировать их.
Подберите наиболее подходящий конвейер аннотирования
Реализуйте конвейер аннотирования, соответствующий вашему проекту, чтобы максимизировать эффективность и минимизировать время выполнения. Например, можно поместить самую популярную метку в начало списка, чтобы аннотаторы не тратили время на её поиск. Также можно настроить процесс аннотации, разбив его на этапы.
Сохраняйте открытость коммуникации
Создайте линию связи с сотрудниками и поддерживайте общение с ключевым руководством. Можно обеспечить эффективную коммуникацию, организовав регулярные совещания и создав групповой канал.
Обеспечьте регулярную обратную связь
Сообщайте сотрудникам об ошибках аннотирования для упрощения процесса QA. Регулярная обратная связь помогает им выработать понимание инструкций и повышать качество результатов. Убедитесь, что обратная связь не противоречит инструкциям по аннотированию. Если вы найдёте ошибку, не прояснённую в инструкции, дополните её и сообщите об изменениях сотрудникам.
Выполните пилотный проект
Всегда начинайте с малого. Задействуйте сотрудников, инструкции по аннотированию и рабочие процессы для тестирования, выполнив пилотный проект. Это поможет вам определить нужное для завершения время, оценить производительность разметчиков и QA, а также усовершенствовать инструкции и процессы перед началом основного проекта.
Как компании размечают свои данные?
Для разметки данных требуются время и деньги. Прежде чем выбирать, как размечать свои данные, учтите свой бюджет и желаемое время завершения проекта.
На что обращать внимание при выборе платформы разметки данных?
Для высококачественных данных требуется команда опытных разметчиков данных с надёжным инструментарием. Можно или купить платформу, или создать её самостоятельно, если вы не можете найти подходящую для себя. На что обращать внимание при выборе платформы для проекта по разметке данных?
Имеющиеся инструменты
Прежде чем искать платформу разметки, подумайте, какие инструменты подходят для вашего проекта. Возможно, вам нужно выделение многоугольниками для разметки автомобилей, или ограничивающие прямоугольники с возможностью поворота для разметки контейнеров. Чтобы разметка была максимально качественной, убедитесь, что выбираемая вами платформа содержит нужные вам инструменты. Продумывайте всё на пару шагов вперёд и разберитесь, какие инструменты разметки могут понадобиться вам в будущем. Зачем вкладывать время и ресурсы в платформу разметки, которую вы не сможете использовать для будущих проектов? Обучение сотрудников новой платформе требует времени и денег, поэтому продумывание заранее сэкономит ваши ресурсы.
Интегрированная система управления
Эффективное управление тоже является строительным блоком успешного проекта по разметке данных. Поэтому выбранная платформа разметки данных должна содержать интегрированную систему управления для управления проектами, данными и пользователями. Надёжная платформа разметки также должна позволять менеджерам проектов отслеживать их прогресс и продуктивность пользователей, обеспечивать возможность обсуждения с аннотаторами неверно размеченных данных, реализовывать рабочий процесс аннотирования, контроля и редактирования меток, а также отслеживания контроля качества.
Процесс контроля качества
Точность данных определяет качество модели обучения. Убедитесь, что выбираемая платформа разметки имеет процесс контроля качества, позволяющий менеджеру проекта контролировать качество размеченных данных. Учтите, что кроме надёжной системы контроля качества сервисы аннотирования данных должны иметь обучение, проверку и профессиональное управление.
Гарантии конфиденциальности и безопасности
Самым важным аспектом должна быть конфиденциальность ваших данных. Выберите защищённую платформу разметки, которой можно доверить уязвимые данные.
Техническая поддержка и документация
Убедитесь, что выбираемая платформа аннотирования данных предоставляет техническую поддержку посредством полной и обновляемой документации, а также имеет активный отдел поддержки. Технические проблемы могут возникнуть в любое время, и для минимизации помех в работе для их устранения вам должен быть доступен отдел поддержки. Перед тем, как покупать подписку на платформу, спросите у отдела поддержки, как он будет устранять технические проблемы.
Computer Vision Annotation Tool: универсальный подход к разметке данных
Обновлено: Июль, 2020
Нижегородский офис компании Intel, помимо прочего, занимается разработкой алгоритмов компьютерного зрения на основе глубоких нейронных сетей. Многие наши алгоритмы публикуются в репозитории Open Model Zoo. Для обучения моделей требуется большое число размеченных данных. Теоретически, существует много способов подготовить их, однако наличие специализированного программного обеспечения многократно ускоряет этот процесс. Так, в целях повышения эффективности и качества разметки, мы разработали собственный инструмент – Computer Vision Annotation Tool (CVAT).

Конечно, на просторах Интернета можно найти немало аннотированных данных, но здесь существуют некоторые проблемы. Например, постоянно возникают новые задачи, для которых таких данных просто нет. Другой вопрос заключается в том, что не все данные пригодны для использования при разработке коммерческих продуктов, по причине их лицензионных соглашений. Таким образом, кроме разработки и тренировки алгоритмов, наша деятельность включает и разметку данных. Это достаточно длительный и трудоемкий процесс, который неразумно было бы возлагать на плечи разработчиков. Например, для обучения одного из наших алгоритмов было размечено около 769 000 объектов за более, чем 3100 человеко-часов.
Существует два варианта решения проблемы:

Конечно, у нас не стояло цели создать “15-ый стандарт”. Первое время мы использовали готовое решение – Vatic, но в процессе работы аннотационная и алгоритмические команды предъявляли к нему все новые и новые требования, реализация которых в итоге привела к полному переписыванию программного кода.
Общие сведения
Computer Vision Annotation Tool (CVAT) – это инструмент с открытым исходным кодом для разметки цифровых изображений и видео. Основной его задачей является предоставление пользователю удобных и эффективных средств разметки наборов данных. Мы создаем CVAT как универсальный сервис, поддерживающий разные типы и форматы разметки.
Для конечных пользователей CVAT – это web-приложение, работающее в браузере. Он поддерживает разные сценарии работы и может быть использован как для персональной, так и для командной работы. Основные задачи машинного обучения с учителем в области обработки изображений можно разбить на три группы:
Как было сказано ранее, CVAT поддерживает ряд дополнительных компонентов, реализованных в виде serverless функций. Среди них:
Deep Learning Deployment Toolkit в составе OpenVINO Toolkit – позволяет запускать пользовательские модели нейронных сетей для получения автоматической аннотации…
Tensorflow Object Detection API – используется для автоматической разметки объектов. CVAT дает возможность использовать разные модели среди обученных для задач детектирования и сегментации.
Алгоритм Deep Extreme Cut добавляет возможность получения маски объекта из его крайних (extreme) точек.
Logstash, Elasticsearch, Kibana – позволяют визуализировать и анализировать накопленные клиентами логи. Это может применяться, например, для мониторинга процесса разметки или поиска ошибок и причин их возникновения.

Разметка данных
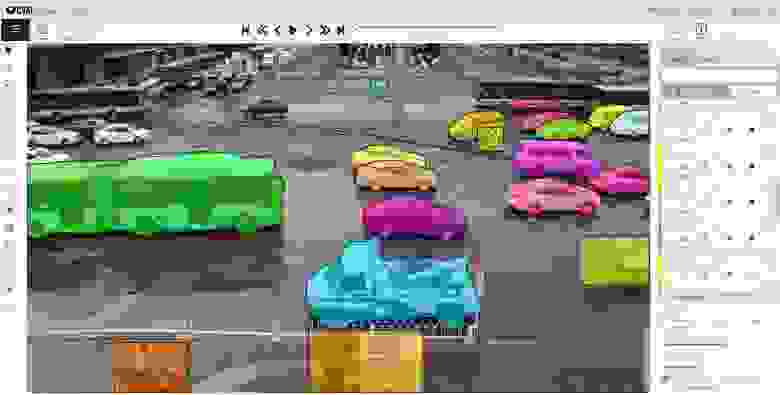
Доступны также разные инструменты автоматизации (копирование, размножение на другие кадры, интерполяция, предварительная разметка с TF OD API), визуальные настройки, множество горячих клавиш, поиск, фильтрация и другая полезная функциональность. В окне настроек можно изменять ряд параметров для более комфортной работы.
Диалоговое окно помощи содержит множество поддерживаемых сочетаний горячих клавиш и некоторые другие подсказки.
Процесс разметки можно увидеть в примерах ниже.
CVAT может выполнять линейную интерполяцию фигур и атрибутов между ключевыми кадрами видео. За счет этого аннотация на множестве кадров выводится автоматически.
Для сценария классификации был разработан Attribute Annotation Mode, который позволяет ускоренно аннотировать атрибуты за счет концентрации внимания разметчика на одном определенном свойстве. Кроме того, разметка здесь происходит за счет использования «горячих клавиш».
С помощью полигонов поддерживаются сценарии semantic segmentation и instance segmentation. Разные визуальные настройки облегчают процесс валидации.
История и эволюция
Первое время у нас не было какой-либо унификации и каждая задача разметки выполнялась своими инструментами, в основном – написанными на С++ с использованием библиотеки OpenCV. Эти инструменты ставились локально на машины конечных пользователей, не было механизма разделения данных, общего конвейера постановки и разметки задач, многие вещи приходилось делать вручную.
Отправной точкой истории CVAT можно считать конец 2016 года, когда в качестве инструмента разметки был внедрен Vatic, интерфейс которого представлен ниже. Vatic имел открытый исходный код и вводил некоторые замечательные, общие идеи, такие как, например, интерполяция разметки между ключевыми кадрами на видео, или клиент-серверная архитектура приложения. Однако в целом, он предоставлял довольно скромную функциональность, поэтому многое мы дорабатывали сами.

Так, например, за первые полгода работы с ним была реализована возможность аннотирования изображений, добавлены пользовательские атрибуты объектов, разработана страничка со списком существующих задач и возможностью добавления новых через web интерфейс.
В течение второй половины 2017 года мы внедрили Tensorflow Object Detection API в качестве метода получения предварительной разметки. Было много мелких доработок клиента, [добавлены новые фичи], и в какой-то момент мы столкнулись с тем, что клиентская часть стала работать очень медленно. Оказалось, что с ростом размера задач, время их открытия увеличивалось пропорционально количеству кадров и размеченных данных, UI тормозил из-за неэффективного представления размечаемых объектов, из-за чего часто терялся прогресс за часы работы. Производительность в основном проседала на задачах с изображениями, поскольку фундамент тогдашней архитектуры изначально был спроектирован для работы с видео. Проявилась необходимость полного изменения клиентской архитектуры, с чем мы успешно справились. Большинство проблем с производительностью на тот момент ушло. Web интерфейс стал работать намного шустрее и стабильнее. Стала возможной разметка бóльших задач. В тот же период была попытка внедрить unit-тестирование, для обеспечения, в какой-то мере, автоматизации проверок при изменениях. Мы настроили QUnit, Karma, Headless Chrome в Docker-контейнере, написали какие-то тесты, запустили все это на CI. Тем не менее, большое количество кода клиентской части все еще не покрыто тестами. Еще одно нововведение представляло из себя систему логирования действий пользователей с последующими поиском и визуализацией на основе ELK Stack. Она позволяет мониторить процесс работы аннотаторов и искать сценарии действий, приводящие к программным исключениям.
В первом половине 2018 года мы расширили клиентскую функциональность. Был добавлен Attribute Annotation Mode, реализующий эффективный сценарий разметки атрибутов, идею которого мы позаимствовали у коллег и обобщили; появились возможности фильтрации объектов по целому ряду признаков, подключения общего хранилища для загрузки данных при постановке задач с просмотром его через браузер и многие другие. Задачи становились объемнее и снова стали возникать проблемы с производительностью, но на этот раз узким местом оказалась уже серверная часть. Проблема Vatic была в том, что он содержал много самописного кода для задач, которые можно было проще и эффективнее решить с помощью готовых решений. Так мы решили переделать серверную часть. В качестве серверного фреймворка мы выбрали Django, во многом из-за его популярности и доступности многих вещей, что называется, “из коробки”. После переделки серверной части, когда от Vatic ничего не осталось, мы решили, что сделали уже достаточно объемную работу, которой можно поделиться с сообществом. Так было принято решение идти в open source. Получить разрешение на это внутри большой компании – достаточно тернистый процесс. Для этого существует большой список требований. В том числе, нужно было придумать имя. Мы набросали варианты и провели серию опросов среди коллег. В итоге, наш внутренний инструмент получил имя CVAT, а 29 июня 2018 года исходный код был опубликован на GitHub в организации OpenCV под лицензией MIT и с начальной версией 0.1.0. Дальнейшая разработка проходила в публичном репозитории.
В 2019 году мы столкнулись с очередной порцией проблем. Во первых, опять увеличился средний размер задачи и количество объектов в ней. Интерфейс работал медленнее, хотя и сохранял стабильность, в сравнении с предыдущей версией. Во вторых, наши пользователи столкнулись с проблемами интеграции CVAT в качестве компонента в сторонние сервисы. Было много высоко связного кода и, например, было чрезвычайно сложно взять только логическую часть инструмента, переписав пользовательский интерфейс. Кто-то интегрировал CVAT через iframe, кто-то интегрировал только серверную часть, которая имела определенный API и была относительно обособленной. Наконец, UI был написан с применением «старой школы» – HTML, CSS, JavaScript, JQuery. UI компоненты были самописные, что не слишком красиво и быстро в реализации. Их расширение требовало значительных трудозатрат, а обновление зачастую было не оптимизировано по скорости (операции с DOM, как известно, одни из самых медленных).
Новая реализация, в конечном счете принесла модульность и использование современных фронтенд технологий. В качестве языка — типизированный диалект JS — TypeScript. Система сборки основана на Webpack и Babel. В качестве UI библиотек и библиотеки управления состоянием: React, Antd, Redux. Клиентская часть состоит из следующих модулей: cvat-core, cvat-data, cvat-canvas, cvat-ui, о смысле которых мы поговорим ниже.
Мы подвели краткий обзор истории CVAT до настоящего времени (лето 2020 года) и рассмотрели наиболее существенные события. Более подробно об истории изменений всегда можно почитать в changelog.
Внутреннее устройство

Для упрощения установки и развертывания CVAT использует контейнеры Docker. Система состоит из нескольких контейнеров. В контейнере CVAT выполняется процесс supervisord, который порождает несколько процессов Python в среде Django. Один из них – wsgi server, который занимается обработкой клиентских запросов. Другие процессы – rq workers, служат для обработки «долгих» задач из очередей Redis: default и low. К таким задачам относятся те, что не могут быть обработаны в течение одного пользовательского запроса (постановка задачи, подготовка аннотационного файла, разметка с TF OD API и другие). Количество workers может быть настроено в файле конфигурации supervisord.
Среда Django взаимодействует с двумя серверами баз данных. Сервер Redis хранит состояния очередей задач, а база данных CVAT содержит всю информацию о задачах, пользователях, аннотации и т.д. В качестве СУБД для CVAT используется PostgreSQL (и SQLite 3 при разработке). Все данные хранятся на подключаемом разделе (cvat db volume). Разделы используются там, где необходимо избежать потери данных при обновлении контейнера. Таким образом, в контейнер CVAT монтируются:
На уровне исходного кода CVAT состоит из множества приложений Django:

Клиентская часть состоит из нескольких модулей:
CVAT-CORE – библиотека предоставления ключевой логики (получение и изменение объектов и задач, взаимодействие с сервером, управление логами и т.д.). Реализована на JavaScript, методы API покрыты тестами с использованием Jest.
CVAT-DATA – клиентская часть организации продвинутой системы стриминга данных. Производит на клиенте разархивирование или декодирование чанков медиа данных, получаемых с сервера. Реализована на JavaScript.
CVAT-CANVAS – компонент, предоставляющий холст для отображения изображения и рисования на нем объектов. В основе лежит технология SVG и библиотека SVG.js. Реализован на TypeScript.
CVAT-UI – пользовательский интерфейс. Реализован с помощью React и библиотеки компонентов Antd. Для управления состоянием используется Redux. Реализован на TypeScript.
Направления развития
Придя в open source, мы получили достаточно много позитивных отзывов от пользователей. Оказалось, что работа востребована сообществом. Возникло множество запросов на новую функциональность. И это прекрасно, потому как теперь не только внутренние потребности определяют направления развития CVAT. Направлений этих, в действительности, немало. Вот некоторые из них:
Существует и множество других запросов на функциональность, которая не относится к вышеперечисленному. К сожалению, запросов всегда больше, чем возможностей для их реализации. По этой причине мы призываем сообщество подключаться и активно участвовать в open source разработке. Это не обязательно должны быть крупные вложения – мы будем рады и небольшим, простым изменениям. Мы подготовили инструкцию в которой описана настройка среды разработки, процесс создания ваших PR и многое другое. Как было сказано ранее, пока нет документации для разработчиков, но вы всегда можете обратиться за помощью к нам в чат в Gitter. Поэтому спрашивайте, включайтесь и творите! Всем удачи!