Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Шардирование баз данных
Шардирование (горизонтальное партиционирование) — это принцип проектирования базы данных, при котором логически независимые строки таблицы базы данных хранятся раздельно, заранее сгруппированные в секции, которые, в свою очередь, размещаются на разных, физически и логически независимых серверах базы данных, при этом один физический узел кластера может содержать несколько серверов баз данных. Наиболее типовым методом горизонтального партицирования является применение хеш функции от идентификационных данных клиента, которая позволяет однозначно привязать заданного клиента и все его данные к отдельному и заранее известному экземпляру баз данных («шарду»), тем самым обеспечив практически неограниченную от количества клиентов горизонтальную масштабируемость.
Этот подход принципиально отличается от вертикального масштабирования, которое при росте нагрузки и объёма данных предусматривает наращивание вычислительных возможностей и объёма носителей информации одного сервера баз данных, имеющее объективные физические пределы — максимальное количество поддерживаемых CPU на один сервер, максимальный поддерживаемый объем памяти, пропускная способность шины и т. д.
Шардирование обеспечивает несколько преимуществ, главное из которых — снижение издержек на обеспечение согласованного чтения (которое для ряда низкоуровневых операций требует монополизации ресурсов сервера баз данных, внося ограничения на количество одновременно обрабатываемых пользовательских запросов, вне зависимости от вычислительной мощности используемого оборудования). В случае шардинга логически независимые серверы баз данных не требуют взаимной монопольной блокировки для обеспечения согласованного чтения, тем самым снимая ограничения на количество одновременно обрабатываемых пользовательских запросов в кластере в целом.
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
Критерий шардинга — какой-то параметр, который позволит определять, на каком именно сервере лежат те или иные данные.
Содержание
Подход с применением шардирования баз данных
Шардинг и репликация
Репликация
Репликация — это синхронное или асинхронное копирование данных между несколькими серверами. Ведущие сервера называют мастерами (master), а ведомые сервера — слэйвами (slave). Мастера используются для изменения данных, а слэйвы — для считывания. В классической схеме репликации обычно один мастер и несколько слэйвов, так как в большей части веб-проектов операций чтения на несколько порядков больше, чем операций записи. Однако в более сложной схеме репликации может быть и несколько мастеров.
Шардинг
Шардинг — это прием, который позволяет распределять данные между разными физическими серверами. Процесс шардинга предполагает разнесения данных между отдельными шардами на основе некого ключа шардинга. Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных.
Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы:
Шардинг и репликация — это популярные и мощные техники масштабирования систем работы с данными. Несмотря на примеры для MySQL, эти подходы универсальны и могут применяться для любой технологии.
SQL Azure Federations
Если приложение использует базы данных MS SQL, возникает несколько вопросов. Конечно первое что приходит в голову — организовать кластер из виртуальных машин SQL Server. Решение достаточно простое и хорошо всем знакомое. А что делать, если приложение использует базу данных как сервис (SaaS)? Что если мы не хотим заниматься настройкой кластера SQL Server? Конечно же, если мы говорим о Windows Azure, то в качестве SQL базы данных будет использоваться SQL Azure. Эта база данных поддерживает технологию горизонтального масштабирования (шардинг) называемую SQL Azure Federations. Принцип ее работы очень простой: логически независимые друг от друга строки одной таблицы хранятся в разных базах данных.
Ограничения SQL Azure
Что это дает: во-первых, изоляцию данных друг от друга. Данные одного аккаунта никак не связаны с данными другого. Соответственно, применением технологии шардинга мы можем реализовать не только горизонтальное масштабирование базы данных, но и multi-tenant сценарий.
Увеличивается скорость выборки данных из базы, поскольку сам размер хранящихся в конкретном шарде данных на порядок меньше, чем суммарный объем базы. Однако, в любой технологии есть свои недостатки. Шардинг не исключение. Если вспомнить, архитектуру SQL Azure, то как известно сервис не поддерживает выборку данных из нескольких баз данных одновременно. То есть одна база данных — одно соединение. И шарды — не исключение. То есть, если допустим простейший запрос на возврат количества клиентов в базе данных необходимо выполнить на каждом шарде отдельно.
Пример запроса для конкретного шарда:
Логику же суммирования значений, возвращаемых этим запросом необходимо размещать в приложении. То есть в результате использования федераций часть кода «уйдет» в приложение, поскольку на уровне базы данных некоторые возможности обычного SQL Server ограничены.
Конечно SQL Azure Federations не является панацеей и можно реализовать свой принцип горизонтального масштабирования баз данных. Допустим multi-tenant подход — тоже своего рода горизонтальное масштабирование базы данных. Поскольку данные одного пользователя отделены не только «логически» от данных другого пользователя, но и «физически». Если необходимо добавить нового пользователя — мы конфигурируем для него отдельную базу данных. Вопрос в том, что в логике приложения должен быть механизм «роутинга». То есть приложение должно знать с какой базой данных оно в данный момент работает.
Сама задумка компании Microsoft хорошая. Было бы неплохо получить инструмент позволяющий легко масштабировать базу данных. Однако как правило, перед принятием окончательного решения перейти к использованию SQL Azure Federations, необходимо тщательно провести анализ существующей базы данных, либо продумать до мельчайших деталей архитектуру базы данных, которую будет использовать приложение, а также саму логику приложения по работе с этой базой.
Серверы баз данных, поддерживающие шардирование:
MongoDB поддерживает шардирование с версии 1.6.
Grails поддерживает шардирование путем Grails Sharding Plugin.
Redis база данных с поддержкой шардирования на стороне клиента.
Microsoft поддерживает шардирование в SQL Azure через «федерации».
Практически любой сервер баз данных может быть использован по схеме шардинга, при реализации соответствующего уровня абстракции на стороне клиента. К примеру eBay применяет серверы Oracle в режиме шардинга[1], Facebook[2] и Twitter[3] применяют шардирование поверх MySQL и т. д.
Шардинг и репликация



Масштабирование баз данных — самая сложная задача во время роста проекта. 90% всех усилий обычно приходится как раз на работу, связанную с ростом объема данных и операций с ними. Классическая схема работы приложения с базой данных выглядит так: 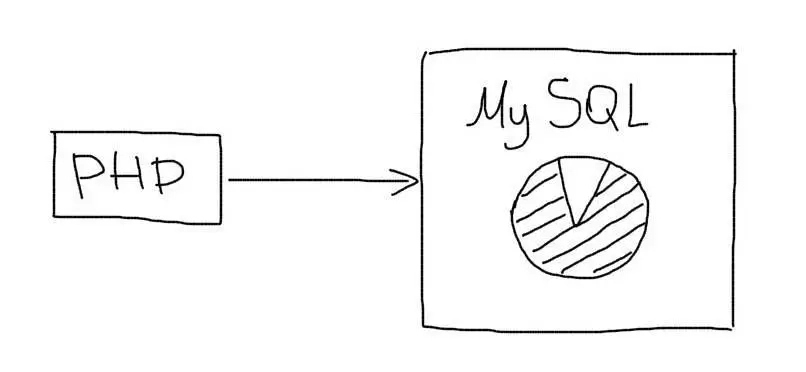
Один сервер базы данных в какой-то момент перестает справляться с нагрузкой. В этот момент и следует применять описанные тут техники масштабирования.
Перед тем, как приступать к масштабированию, необходимо провести анализ медленных запросов и убедиться, что сервер MySQL настроен оптимально.
Стратегии
В основе масштабирования данных лежит тот же принцип, что и в основе масштабирования Web приложений. Это разделение данных на группы и выделение их на отдельные сервера. Существует две основные стратегии — репликация и шардинг.
Репликация
Репликация позволяет создать полный дубликат базы данных. Так, вместо одного сервера у Вас их будет несколько: 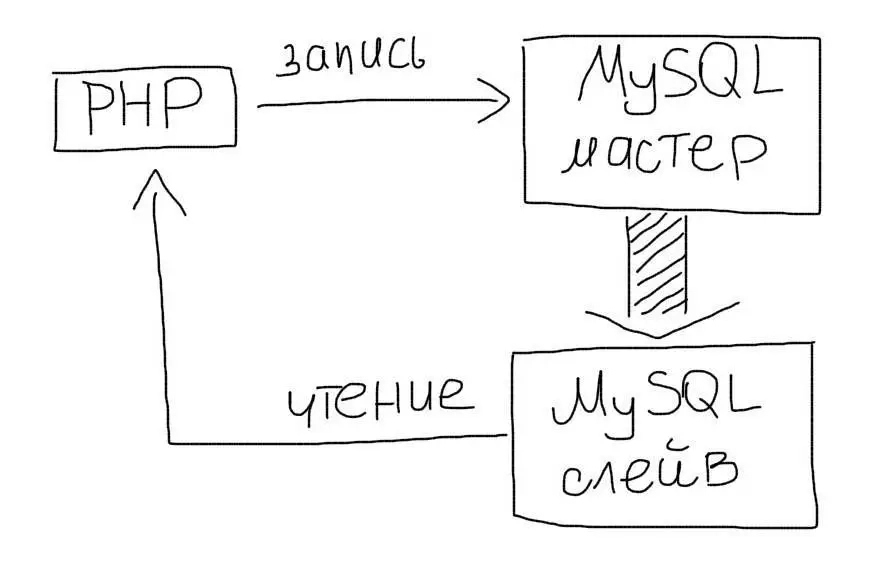
Master-slave
Чаще всего используют схему master-slave:
Репликация позволяет использовать два или больше одинаковых серверов вместо одного. Операций чтения (SELECT) данных часто намного больше, чем операций изменения данных (INSERT/UPDATE). Поэтому, репликация позволяет разгрузить основной сервер за счет переноса операций чтения на слейв.
Работа из приложения
В приложении у Вас будет два соединения с базой данных. Одно — для мастера и одно для слейва:
При выполнении запросов необходимо использовать соответствующее соединение
Репликация обычно поддерживается самой СУБД (например, MySQL) и настраивается независимо от приложения.
Читайте детальнее про настройку, использование и типы репликации данных на примере MySQL.
Следует отметить, что репликация сама по себе не очень удобный механизм масштабирования. Причиной тому — рассинхронизация данных и задержки в копировании с мастера на слейв. Зато это отличное средство для обеспечения отказоустойчивости. Вы всегда можете переключиться на слейв, если мастер ломается и наоборот. Чаще всего репликация используется совместно с шардингом именно из соображений надежности.
Шардинг (sharding)
Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры Вашей базы данных и выполняется прямо в приложении в отличие от репликации: 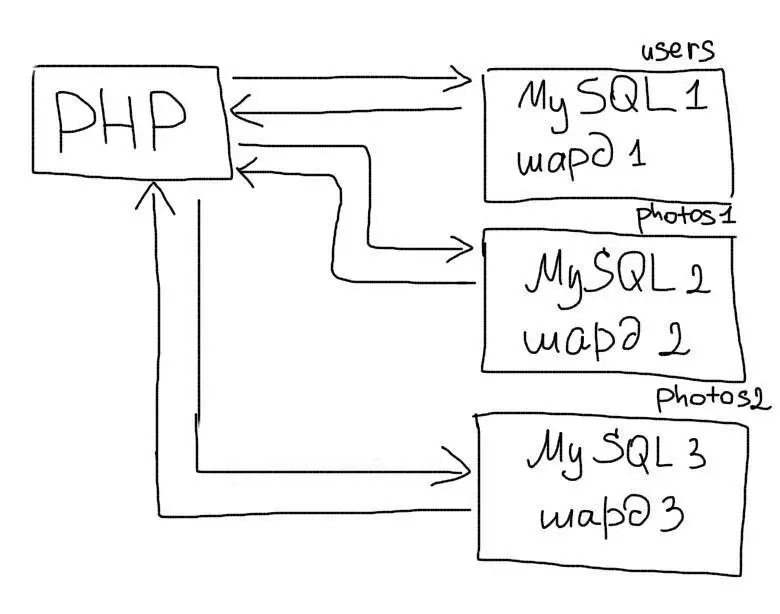
Вертикальный шардинг
Вертикальный шардинг — это выделение таблицы или группы таблиц на отдельный сервер. Например, в приложении есть такие таблицы:
Таблицу users Вы оставляете на одном сервере, а таблицы photos и albums переносите на другой. В таком случае в приложении Вам необходимо будет использовать соответствующее соединение для работы с каждой таблицей:
Для каждой таблицы или группы таблиц будет отдельное соединение
В отличие от репликации, мы используем разные соединения для любых операций, но с определенными таблицами. Читайте подробнее об использовании вертикального шардинга на практике.
Горизонтальный шардинг
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
Допустим, наше приложение работает с огромной таблицей, которая хранит фотографии пользователей. Мы подготовили два сервера (обычно они называются шардами) для этой таблицы. Для нечетных пользователей мы будем работать с первыми сервером, а для четных — со вторым. Таким образом, на каждом из серверов будет только часть всех данных о фотках пользователей. Это будет выглядеть так:
Перед обращением к таблице, мы выбираем нужное нам соединение
Горизонтальный шардинг — это очень мощный инструмент масштабирования данных. Но в то же время и очень нетривиальный. Читайте детально об использовании горизонтального шардинга на практике.
Не следует применять технику шардинга ко всем таблицам. Правильный подход — это поэтапный процесс разделения растущих таблиц. Следует задумываться о горизонтальном шардинге, когда количество записей в одной таблице переходит за пределы от нескольких десятков миллионов до сотен миллионов.
Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы:
Тогда в приложении работа с этой табличкой может выглядеть так:
Читаем данные со слейвов, а записываем на мастер-сервера
Такая схема часто используется не для масштабирования, а для обеспечения отказоустойчивости. Так, при выходе из строя одного из серверов шарда, всегда будет запасной.
Key-value базы данных
Следует отметить, что большинство [p165 Key-value баз данных] поддерживает шардинг на уровне платформы. Например, Memcache. В таком случае, Вы просто указываете набор серверов для соединения, а платформа сделает все остальное:
Мемкеш сам умеет определять нужный сервер для каждого ключа
Самое важное
Шардинг и репликация — это популярные и мощные техники масштабирования систем работы с данными. Несмотря на примеры для MySQL, эти подходы универсальны и могут применяться для любой технологии.
Помните, процесс масштабирования данных — это архитектурное решение, оно не связано с конкретной технологией. Не делайте ошибок наших отцов — не переезжайте с известной Вам технологии на новую из-за поддержки или не поддержки шардинга. Проблемы обычно связаны с архитектурой, а не конкретной базой данных.
Этот текст был написан несколько лет назад. С тех пор упомянутые здесь инструменты и софт могли получить обновления. Пожалуйста, проверяйте их актуальность.
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Как исправить ошибку доступа к базе 1045 Access denied for user
Настройка Master-Master репликации на MySQL за 6 шагов
Примеры ad-hoc запросов и технологии для их исполнения
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Типы и способы применения репликации на примере MySQL
Как создать и использовать составной индекс в Mysql
Настройка Master-Slave репликации на MySQL за 6 простых шагов
Синтаксис и оптимизация Mysql LIMIT
Правильная настройка Mysql под нагрузки и не только. Обновлено.
И как правильно работать с длительными соединениями в MySQL
Запрос для определения версии Mysql: SELECT version()
Check-unused-keys для определения неиспользуемых индексов в базе данных
3 примера установки индексов в JOIN запросах
Анализ медленных запросов с помощью EXPLAIN
Что значит и как это починить
Описание, рекомендации и значение параметра query_cache_size
Быстрый подсчет уникальных значений за разные периоды времени
Использование партиций для ускорения сложных удалений
Правила выбора типов данных для максимальной производительности в Mysql
Включение и использование логов ошибок, запросов и медленных запросов, бинарного лога для проверки работы MySQL
Теория шардирования
Кажется, мы так глубоко погрузились в дебри highload-разработки, что просто не задумываемся о базовых проблемах. Взять, например, шардирование. Чего в нем разбираться, если в настройках базы данных можно написать условно shards = n, и все сделается само. Так-то, он так, но если, вернее когда, что-то пойдет не так, ресурсов начнет по-настоящему не хватать, хотелось бы понимать, в чем причина и как все починить.
Короче, если вы контрибьютили свою альтернативную реализацию хэширования в Cassandra, то вряд ли тут для вас найдутся откровения. Но если нагрузка на ваши сервисы уже прибывает, а системные знания за ней не поспевают, то милости просим. Великий и ужасный Андрей Аксёнов (shodan) в свойственной ему манере расскажет, что шардить плохо, не шардить — тоже плохо, и как это внутри устроено. А еще совершенно случайно одна из частей рассказа про шардинг вообще не совсем про шардинг, а черт знает про что — как объекты на шарды мапить. 
Фотография котиков (хоть они случайно и оказались щеночками) уже как бы отвечает на вопрос, зачем это всё, но начнем последовательно.
Что такое «шардинг»
Если упорно гуглить, то выяснится, что между так называемым партиционированием и так называемым шардингом достаточно размытая граница. Каждый называет все, что хочет, чем хочет. Одни люди различают горизонтальное партиционирование и шардинг. Другие говорят, что шардинг — это определенный вид горизонтального партиционирования.
Единого терминологического стандарта, который был бы одобрен отцами-основателями и в ISO сертифицирован, я не нашел. Личное внутреннее убеждение примерно такое: Partitioning в среднем — это «режем базу на куски» произвольно взятым образом.
Шардирование — это в целом, когда большая таблица в терминах баз или проколлекция документов, объектов, если у вас не совсем база данных, а document store, режется именно по объектам. То есть из 2 млрд объектов выбираются куски не важно, какого размера. Объекты сами по себе внутри каждого объекта не разрезаем на куски, на отдельные колонки не раскладываем, а именно пачками раскладываем в разные места.
Ссылка на презентацию для полноты картины.
Дальше уже пошли тонкие терминологические отличия. Например, условно говоря, разработчики на Postgres могут сказать, что горизонтальное партиционирование — это когда все таблицы, на которые разделена основная таблица, лежат в одной и той же схеме, а когда на разных машинах —это уже шардирование.
В общем смысле, не привязываясь к терминологии конкретной базы данных и конкретной системы управления данными, есть ощущение, что шардирование — это просто нарезка построчно-подокументно и так далее — и все:
Подчеркиваю, типично. В том смысле, что мы все это делаем не просто так, чтобы нарезать 2 млрд документов на 20 таблиц, каждая из которых была бы более manageable, а для того, чтобы распределить это на много ядер, много дисков или много разных физических или виртуальных серверов.
Подразумевается, что мы это делаем для того, чтобы каждый шард — каждый шматок данных — многократно реплицировать. Но на самом деле, нет.
На самом деле, если вы сделаете такую нарезку данных, и из одной гигантской SQL таблицы на MySQL на своем доблестном ноутбуке сгенерируете 16 маленьких табличек, не выходя за рамки ни одного ноутбука, ни одной схемы, ни одной базы данных, и т.д. и т.п. — все, у вас уже шардирование.
Вспомнив иллюстацию с щеночками, это приводит к следующему:
Зачем latency? На одном ядре просканировать таблицу из 2 млрд строк в 20 раз медленнее, чем просканировать 20 таблиц на 20 ядрах, делая это параллельно. Данные слишком медленно обрабатываются на одном ресурсе.
Зачем high availability? Либо нарезаем данные, для того чтобы делать и одно, и другое одновременно, и заодно несколько копий каждого шарда — репликация обеспечивает высокую доступность.
Простой пример «как сделать руками»
Почему примерно? Потому что априори мы не знаем, как распределены id, если от 1 до 32 включительно, то будет ровно по 2 документа, иначе — нет.
Делаем мы это вот зачем. После того, как мы сделали 16 таблиц, мы можем «захавать» 16 того, что нам нужно. Вне зависимости от того, во что мы уперлись, мы можем на эти ресурсы распараллелиться. Например, если не хватает дискового пространства, будет иметь смысл разложить эти таблицы по отдельным дискам.
Все это, к несчастью, не бесплатно. Подозреваю, что в случае с каноническим SQL-стандартом (давно не перечитывал SQL-стандарт, возможно, его давно не обновляли), нет официального стандартизированного синтаксиса для того, чтобы любому SQL-серверу сказать: «Дорогой SQL-сервер, сделай мне 32 шарда и разложи их на 4 диска». Но в отдельно взятых реализациях зачастую есть конкретный синтаксис для того, чтобы сделать в принципе то же самое. В PostgreSQL есть механизмы для партиционирования, в MySQL MariaDB есть, Oracle наверняка это все сделал уже давным-давно.
Тем не менее, если мы это делаем руками, без поддержки базы данных и в рамках стандарта, то платим условно сложностью доступа к данным. Там, где было простое SELECT * FROM documents WHERE теперь 16 x SELECT * FROM docsXX. И хорошо, если мы пытались доставать запись по ключу. Значительно более интересно, если мы пытались доставать ранний диапазон записей. Теперь (если мы, подчеркиваю, как бы дураки, и остаемся в рамках стандарта) результаты этих 16 SELECT * FROM придется объединять в приложении.
Какого изменения производительности ожидать?
Посмотрим, как этого можно добиться. Понятно, что просто поставить настройку в PostgreSQL shards=16, а дальше оно само взлетело — это не интересно. Давайте подумаем, как можно добиться того, чтобы от шардирования в 16 раз мы бы затормозили в 32 — это интересно с той точки зрения, как бы этого не делать.
Наши попытки ускориться либо затормозить всегда будут упираться в классику — в старый добрый закон Амдала (Amdahl law), который говорит, что не бывает идеальной распараллелизации любого запроса, всегда есть некая последовательная часть.
Amdahl law
Всегда есть часть исполнения запроса, которая параллелится, и всегда есть часть, которая не параллелится. Даже если вам кажется, что идеально параллелещийся запрос, как минимум сбор строки результата, которую вы собираетесь отослать на клиента, из строк, полученных с каждого шарда, всегда есть, и он всегда последовательный.
Всегда есть какая-то последовательная часть. Она может быть крохотной, абсолютно незаметной на общем фоне, она может быть гигантской и, соответственно, сильно влияющей на параллелизацию, но она есть всегда.
Кроме того, её влияние меняется и может ощутимо подрасти, например, если мы нарежем нашу таблицу — давайте поднимем ставки — из 64 записей на 16 таблиц по 4 записи, эта часть изменится. Конечно же, судя по таким гигантским объемам данных, мы работаем на мобильном телефоне и 86 процессоре 2 МГц, у нас и файлов-то не хватает, которые можно одновременно держать открытыми. Видимо, с такими вводными, мы по одному файлу за раз открываем.
Это стандартная картинка про закон Амдала. Она не очень читаема, но важно то, что линии, которые должны в идеале быть прямыми и линейно расти, упираются в асимптоту. Но поскольку график из интернета нечитаемый, я изготовил, на мой взгляд, более наглядные таблицы с цифрами.
Предположим, что у нас есть некая сериализованная часть обработки запроса, которая занимает всего 5%: serial = 0.05 = 1 / 20.
Интуитивно казалось бы, что при сериализованной части, которая занимает всего 1/20 от обработки запроса, если мы распараллелим обработку запроса на 20 ядер, она станет примерно в 20, в худшем случае в 18, раз быстрее.
На самом деле математика — штука бессердечная:
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)
Оказывается, что если аккуратно посчитать, при сериализованной части в 5%, ускорение будет в 10 раз (10,3), а это 51% по сравнению с теоретическим идеальным.
| 8 cores | = 5.9 | = 74% |
| 10 cores | = 6.9 | = 69% |
| 20 cores | = 10.3 | = 51% |
| 40 cores | = 13.6 | = 34% |
| 128 cores | = 17.4 | = 14% |
Использовав 20 ядер (20 дисков, если угодно) на ту задачу, над которой раньше трудилось одно, мы даже теоретически ускорение больше 20 раз никогда не получим, а практически — гораздо меньше. Причем, с увеличением числа параллелей, неэффективность сильно растет.
Когда остается только 1% сериализованной работы, а 99 % параллелится, значения ускорения несколько улучшаются:
| 8 cores | = 7.5 | = 93% |
| 16 cores | = 13.9 | = 87% |
| 32 cores | = 24.4 | = 76% |
| 64 cores | = 39.3 | = 61% |
Для совершенно термоядерного запроса, который натурально часами исполняется, и подготовительная работа и сборка результата занимают очень мало времени (serial = 0.001), мы увидим уже хорошую эффективность:
| 8 cores | = 7.94 | = 99% |
| 16 cores | = 15.76 | = 99% |
| 32 cores | = 31.04 | = 97% |
| 64 cores | = 60.20 | = 94% |
Обратите внимание, 100% мы не увидим никогда. В особо хороших случаях можно увидеть, например, 99,999%, но не ровно 100%.
Как зашардить и втормозить в N раз?
Можно так зашардить и втормозить ровно в N раз:
Все остальное время обработки простого запроса будут занимать не распараллеливаемые операции разбора запроса, подготовки плана и т.д. То есть тормозит не чтение записи.
Если мы разобьем данные на 16 таблиц и будем запускать последовательно, как принято в языке программирования PHP, например, (он не очень хорошо умеет запускать асинхронные процессы), то как раз и получим замедление в 16 раз. А, возможно, даже больше, потому что добавятся еще и network round-trips.
Внезапно при шардировании важен выбор языка программирования.
Помним про выбор языка программирования, потому что если посылать запросы к базе данных (или поисковому серверу) последовательно, то откуда взяться ускорению? Скорее, появится замедление.
Байка из жизни
Если выбираете С++, пишите на POSIX Threads, а не на Boost I/O. Я видел прекрасную библиотеку от опытных разработчиков из самого Oracle и MySQL, которые написали общение с сервером MySQL на Boost. Видимо, их на работе заставляли писать на чистом C, а тут удалось развернуться, взять Boost с асинхронным I/O и т.д. Одна проблема — этот асинхронный I/O, который теоретически должен был гонять 10 запросов в параллели, почему-то внутри имел незаметную точку синхронизации. При запуске 10 запросов в параллель, они исполнялись ровно в 20 раз медленнее одного, потому что 10 раз на сами запросы и еще по разу на точку синхронизации.
Вывод: пишите на языках, которые хорошо реализуют параллельный запуск и ожидание разных запросов. Не знаю, честно говоря, что именно тут посоветовать, кроме Go. Не только потому, что я очень люблю Go, а потому что ничего более подходящего я не знаю.
Не пишите на негодных языках, на которых не сумеете запустить 20 параллельных запросов к базе данных. Либо при каждой возможности не делайте это все руками — понимайте, как устроено, но не делайте вручную.
Байка из A/B теста
Еще иногда можно затормозить, потому что привыкли, что все работает, и не заметили, что сериализованная часть, во-первых, есть, во-вторых, большая.
Так может, надо не руками делать шардинг, а просто по-человечески
сказать базе данных: «Делай!»
Disclaimer: я не очень знаю, как сделать-то правильно. Я типа с неправильного этажа.
Я всю свою сознательную жизнь пропагандирую религию под названием «алгоритмический фундаментализм». Она вкратце формулируется очень просто:
Ты не хочешь ничего делать действительно руками, но при этом крайне полезно знать, как оно устроено внутри. Чтобы в тот момент, когда в базе что-то пойдет не так, ты хотя бы понимал, что там пошло не так, как оно устроено внутри и примерно, как это можно починить.
Давайте рассмотрим варианты:
Про полуавтомат
Местами изыски информационных технологий внушают хтонический ужас. Например, MySQL из коробки не имел реализации шардинга до определенных версий точно, тем не менее размеры баз, эксплуатируемых в бою, дорастают до неприличных величин.
ProxySQL в целом, конечно же, полноценное решение enterprise-класса для open source, для роутинга и прочего. Но одна из решаемых задач — это шардинг для базы данных, которая сама по себе шардить по-человечески не умеет. Понимаете, нет рубильника «shards=16», приходится либо в приложении переписывать каждый запрос, а их местами много, либо между приложением и базой данных ставить некий промежуточный слой, который смотрит: «Хм… SELECT*FROM documents? Да его надо разорвать на 16 маленьких SELECT*FROM server1.document1, SELECT*FROM server2.document2 — к этому серверу с таким логином/паролем, к этому с другим. Если один не ответил, то. » и т.д.
Ровно этим могут заниматься промежуточные нашлёпки. Они есть чуть менее, чем для всех баз данных. Для PostgreSQL, насколько я понимаю, одновременно есть и какие-то встроенные решения (PostgresForeign Data Wrappers, по-моему, встроен в сам PostgreSQL), есть внешние нашлёпки.
Конфигурирование каждой конкретной нашлёпки — это отдельная гигантская тема, которая не поместится в один доклад, поэтому мы обсудим только базовые концепции.
Давайте лучшее поговорим немного про теорию кайфа.
Абсолютная идеальная автоматика?
Вся теория кайфа в случае шардирования в этой букве F(), базовый принцип всегда один и тот же грубо: shard_id = F(object).
Шардирование — это вообще про что? У нас есть 2 миллиарда записей (или 64). Мы их хотим раздробить на несколько кусков. Возникает неожиданный вопрос — как? По какому принципу я свои 2 миллиарда записей (или 64) должен разбросать на доступные мне 16 серверов?
Латентный математик в нас должен подсказать, что в конечном итоге всегда есть некая волшебная функция, которая по каждому документу (объекту, строке и т.д.) определит, в какой кусок его положить.
Если углубиться дальше внутрь математики, эта функция всегда зависит не только от самого объекта (самой строчки), но еще от внешних настроек типа общего количества шардов. Функция, которая для каждого объекта должна сказать, куда его класть, не может же возвращать значение больше, чем есть серверов системе. И функции немного разные:
Какие бывают F()?
Их можно придумать много разных и много разных механизмов реализации. Примерная краткая сводка:
Есть чуть более интеллектуальные методы шардить по воспроизводимой или даже консистентной хэш-функции, либо шардить по какому-то атрибуту. Пройдемся по каждому методу.
F = rand()
Раскидывать радомом — не очень правильный метод. Одна проблема: раскидали мы наши 2 млрд записей на тысячу серверов случайным образом, и не знаем, где запись лежит. Нам надо вытащить user_1, а где он, не знаем. Идем на тысячу серверов и перебираем все — как-то это неэффективно.
F = somehash()
Давайте раскидывать юзеров по-взрослому: считать воспроизводимую хэш-функцию от user_id, брать остаток от деления на число серверов и обращаться сразу к нужному серверу.
А зачем мы это делаем? А затем, что у нас highload и в один сервер у нас больше ничего не влазит. Если бы влазило, жизнь была бы такая простая.
Отлично, ситуация уже улучшилась, чтобы получить одну запись, мы идем на один заранее известный сервер. Но если у нас есть диапазон ключей, то во всем этом диапазоне надо перебрать все значения ключей и в пределе сходить либо на столько шардов, сколько у нас ключей в диапазоне, либо вообще на каждый сервер. Ситуация, конечно, улучшилась, но не для всех запросов. Некоторые запросы пострадали.
Естественное шардирование (F = object.date % num_shards)
Иногда, то есть часто, 95% трафика и 95% нагрузки — это запросы, у которых есть какое-то естественное шардирование. Например, 95% условно социально-аналитических запросов затрагивает данные только за последние 1 день, 3 дня, 7 дней, а оставшиеся 5% обращаются к нескольким последним годам. Но 95% запросов, таким образом, естественно шардированы по дате, интерес пользователей системы сфокусирован на последних нескольких днях.
В этом случае можно разделить данные по дате, например, по одному дню, и за ответом на запрос на отчет за какой-то день или объект из этого дня на этот шард и идти.
Жизнь улучшается — мы теперь не только знаем расположение конкретного объекта, но и про диапазон тоже знаем. Если у нас спрашивают не диапазон дат, а диапазон других колонок, то, конечно, придется перебирать все шарды. Но по условиям игры у нас всего 5 % таких запросов.
Вроде бы мы придумали идеальное решение всего, но есть две проблемы:
Проблема решается ужимками, прыжками и припарками, то есть повышением количества реплик для горящего текущего дня, потом постепенным снижением количества реплик, когда этот день становится прошлым и переходит в архив. Тут нет идеального решения под названием «надо просто волшебной хэш-функцией размазать данные по кластеру не так».
Формально мы знаем теперь знаем «всё». Правда, мы не знаем одну гигантскую головную боль и две головные боли поменьше.
1. Простая боль: плохо размазало
Это пример из учебника, который в бою почти не встречается, но вдруг.
Чтобы поймать, надо смотреть размеры шардов. Проблему мы обязательно увидим в момент, когда у нас один шард либо перегреется, либо станет в 100 раз больше других. Починить можно просто заменой ключа или функции шардирования.
Это простая проблема, честно говоря, я не думаю, что хотя бы один человек из ста нарвётся на это в жизни, но вдруг хоть кому-то поможет.
2. «Непобедимая» боль: агрегация, join
Как делать выборки, которые джойнят миллиард записей из одной таблицы на миллиард записей из другой таблицы?
Если вы в первой таблице распределили миллиард записей на тысячу серверов, чтобы они быстрее работали, во второй таблице сделали то же самое, то естественно тысяча на тысячу серверов должны между собой попарно говорить. Миллион связей работать хорошо не будет. Если мы делаем запросы к базе (поиску, хранилищу, document store или распределенной файловой системе), которые плохо ложатся на шардинг, эти запросы будут дико тормозить.
Немаловажный момент — какие-то запросы всегда неудачно размажутся и будут тормозить. Важно попытаться минимизировать их процент. Как следствие, не надо делать гигантские джойны с миллиардом на миллиард записей. Если есть возможность маленькую таблицу, относительно которой джойнишь в гигантской расшарденной таблице, реплицировать на все узлы, надо сделать это. Если джойны на самом деле локальны каким-то образом, например, есть возможность пользователя и его его посты разместить рядом, зашардить их одинаково, и все джойны делать в пределах одной машины — надо делать именно так.
Это отдельный курс лекций на три дня, поэтому переходим к последней адской боли и к разным алгоритмам борьбы с ней.
3. Сложная/длинная боль: решардинг
Готовьтесь: если вы зашардили ваши данные первый раз в жизни, то в среднем еще раз пять вы их порешардите обязательно.
Сколько кластер не конфигурируй, всё равно решардить.
Если вы очень умны и удачливы, то перешардите, минимум, один раз. Но один раз вы обязательно, потому что в тот момент, когда вы думаете, что пользователю достаточно 10 единиц, кто-то прямо в этот момент пишет запрос на 30, а в планах имеет запрос на 100 единиц неизвестных ресурсов. Шардов всегда не хватит. Со первой схемой шардинга вы в любом случае промахнетесь — всегда придется либо увеличивать количество серверов докидывать, либо что-то еще делать — в общем, как-то данные переукладывать.
Хорошо, если у нас приятные степени двойки: было 16 шардов-серверов, стало 32. Веселее, если было 17, стало 23 — два вазимно простых числа. Как же это делают базы данных, может быть, у них есть какая-то магия внутри?
Правильный ответ: нет, никакой магии внутри нет, у них внутри есть ад.
Дальше рассмотрим, что можно сделать «руками», авось поймем «как автоматом».
В лоб #1. Переселить всё
В лоб #2. Переселить половину
Следующее наивное улучшение — давайте откажемся от такой дурацкой схемы — запретим 17 машин решардить в 23, и всегда будем решардить 16 машин в 32 машины! Тогда нам по теории придется переложить ровно половину данных, и на практике мы тоже сможем это сделать.
Обратите внимание, дополнительное дробление кластера по степеням двойки в данном случае еще и оптимально. В любом случае, добавляя 16 машин в кластер из 16, мы обязаны половину данных переложить — ровно половину и переложим.
Хорошо, но неужели человечество не изобрело ничего больше — возникает вопрос у пытливого ума.
Веселее #3. Consistent hashing
Конечно, здесь обязательна картинка с кругом про consistent hashing 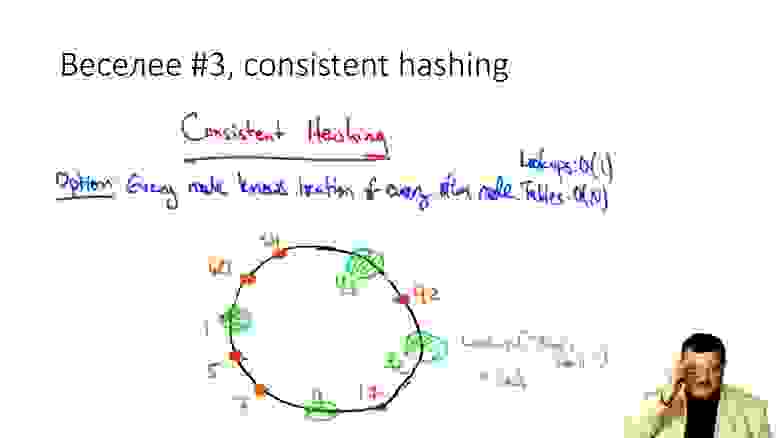
Если загуглить «consistent hashing», то обязательно вылезет круг, вся выдача кругами заселена.
Идея: давайте идентификаторы шардов (хэши) нарисуем на круге, а поверх отметим захэшированные идентификаторы серверов. Когда надо добавить сервер, ставим новую точку на круг, и то, что оказалось близко к ней (и только то, что оказалось близко к ней), переселяем.
Решать эту проблему принято последней строчкой виртуальной ноды. Каждый узел, каждый сервер на круге обозначается не одной точкой. Добавляя сервер, шард и т.д., мы добавляем несколько точек. Каждый раз, когда мы что-то удаляем, соответственно, удаляем несколько точек и перекладываем небольшую часть данных.
Я рассказываю про этот космос с кругами, потому что, например, внутри Cassandra именно такая схема. То есть, когда она у вас начала записи между нодами гонять, знайте, что круг смотрит на вас и, наверное, не одобряет.
Тем не менее, по сравнению с первыми способами жизнь улучшилась — мы уже просматриваем при добавлении/удалении шарда не все записи, а только часть, и перекладываем только часть.
Внимание, вопрос: нельзя ли улучшить еще? И еще улучшить и равномерность загрузки шардов? — Говорят, что можно!
Веселее #4. Rendezvous/HRW
Следующая простая идея (материал же обучающий, поэтому ничего сложного): shard_id = arg max hash(object_id, shard_id).
Почему она называется Rendezvous hashing, я не знаю, но знаю, почему она называется Highest Random Weight. Ее очень просто визуализировать следующим образом: 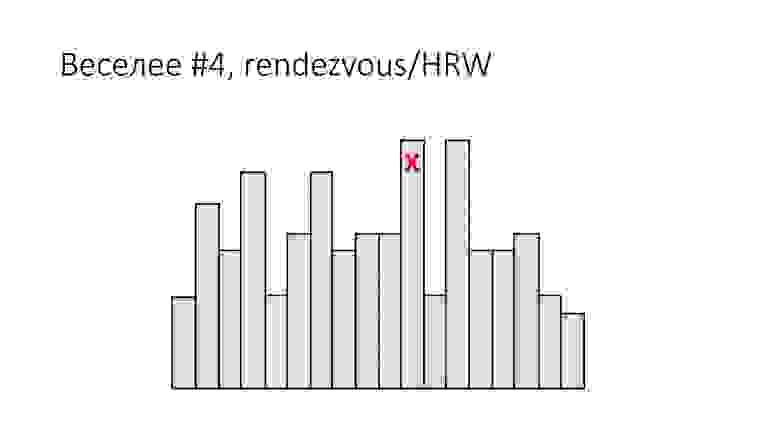
У нас есть, например, 16 шардов. Для каждого объекта (строки), который надо куда-то положить, вычисляем 16 хэшей, зависящих от объекта с номера шарда. У кого самое высокое значение хэш-функции, тот и победил.
Это так называемый HRW-hashing, он же Rendezvous hashing. Тупая как палка схема вычисления номера шарда, во-первых, на глаз проще кругов и дает равномерную загрузку, с другой стороны.
Единственный минус в том, что добавление нового шарда у нас ухудшилось. Есть риск, что при добавлении нового шарда у нас все-таки какие-то хэши изменятся и может оказаться необходимым просмотреть все. Технология удаление шарда не особо изменилась.
Еще одна проблема, это вычислительно тяжело при большом количестве шардов.
Веселее #5. Еще техники
Интересно, что исследования не стоят на месте и Google каждый год публикует какую-нибудь новую космическую технику:
Веселее #6. Списки
На закусочку самый простой вариант — тупо списки. Зачем нам все эти мегатехники? Мы не хотим, для того чтобы управлять 2 млрд записей, держать в памяти кластера на каждом узле гигантский список object_id на 2 млрд идентификаторов, которые бы отображали расположение объекта.
А что, если взять и сильно проредить этот список? Или даже не сильно?
Давайте хотя бы просто посчитаем. Уверен, что в какой-нибудь из баз данных это используется, но не знаю, в какой. Математика говорит, что это может достаточно неплохо сработать, и, честно говоря, можно даже ручками умудриться сделать.
Повторюсь, вариант простой как палка, сложные космические техники не нужны, и наверняка он где-то работает, но я не нашел где.
Выводы
Есть важная базовая техника под названием шардинг имени еще Галлия Юлия Цезаря: «Разделяй и властвуй, властвуй и разделяй!». Если данные не влазят в один сервер, надо их разбить на 20 серверов.
Узнав это все, должно возникнуть впечатление, что лучше бы не шардить. Если вы решили, что лучше бы не шардить — это правильное ощущение. Если можно добавить за 100$ памяти в сервер и ничего не шардить, то так и надо сделать. При шардировании появится сложная распределенная система с перекачкой данных туда-сюда, укладкой данных неизвестно куда. Если можно этого избежать — нужно этого избежать.
Настраивая шардирование первый раз аккуратно выбирайте F(), думайте про запросы, сеть, и т.п. Но готовьтесь, вероятно, выбирать надо будет 2 раза и хотя бы раз придется все переделать.
О спикере
Обычно, мы на берегу рассказываем о спикере, но в этот раз есть повод для исключения. Андрей Аксёнов стал одним из лауреатов Премии HighLoad++, и всем, для кого ассоциативная цепочка Аксёнов—Sphinx—highload не очевидна, стоит посмотреть ролик.
Об обучающем митапе
Это был материал по выступлению на обучающем митапе Highload User Group. Расскажу немного, что это и зачем.
Мы недавно, осознали, что доклады на большом HighLoad++ уходят все глубже и глубже. На конференции мы не можем повторяться и снова обсуждать, например, вопросы архитектуры. А мест, где можно было бы познакомиться с базовыми концепциями и систематизировать обрывочные знания, нет. Поэтому мы запустили серию обучающих митапов по разработке highload-приложений, сайтов и сервисов.
Будем говорить о масштабировании сервисов и баз данных, нагрузочном тестировании, машинном обучении и нейронных сетях, архитектурах проектов. Всё, что связано с разработкой нестандартных решений с повышенными требованиями по производительности, устойчивости, безопасности и так далее постепенно появится на повестке.
На третьем митапе 24 января в Санкт-Петербурге обсудим паттерны проектирования высоконагруженных систем «Очередь», «Конвейерная обработка». Мероприятие бесплатное, но нужно зарегистрироваться по ссылке в описании митапа. Спикеров и темы опубликуем чуть позже, или можем выслать в рассылке.
Рассылка еще и самый простой способ узнать о новостях, например, что 8 и 9 апреля в Санкт-Петербурге пройдет свой HighLoad++ и уже можно подать заявку или забронировать early bird билет.